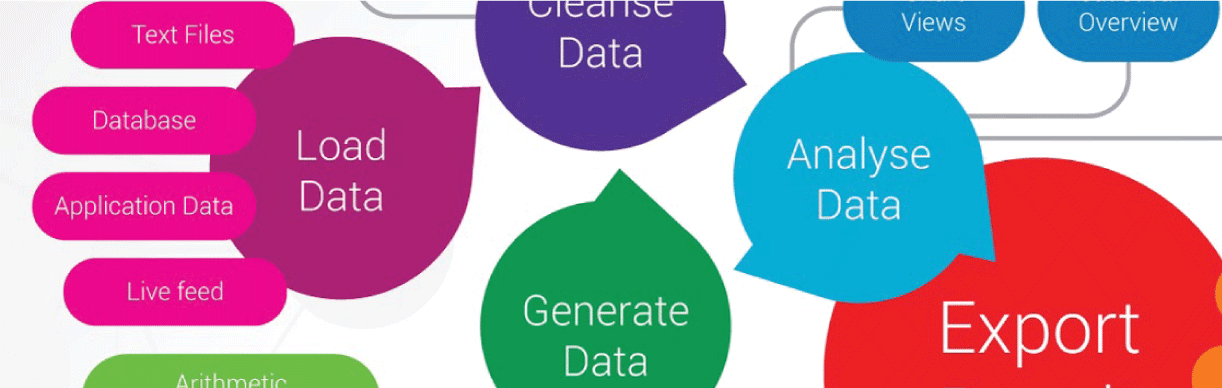
We’re launching a new capability for a broader set of analysis. In addition to running standalone this tool will be seamlessly integrated into with Debrief.
Why Do We Need a New Tool?
Debrief traditionally enjoys a fixed data model, understanding precisely how to exploit, visualise and process each type of data. Over the years analysts do request new data types to be handled with Debrief, and, where the new data type fits the general model of Debrief a new REP message format is introduced, and the data is “knitted into” the rest of the Debrief interface and data flows.
But, recently a body of analysts need to explore a physical phenomena. The data to be handled and the algorithms to process that data aren’t mature enough to be bedded directly into Debrief. So, a more free-form mode of analysis is required.
What Is This New Tool?
In response to this, we’re adding some new capabilities to Debrief to allow ad-hoc, unpredictable data types to be loaded into the application. Debrief won’t know about this data in advance, but tools will be provided to either conduct a generic analysis of that data, or for the user to add sufficient context to the data to allow relevant operations and visualisations to be provided.
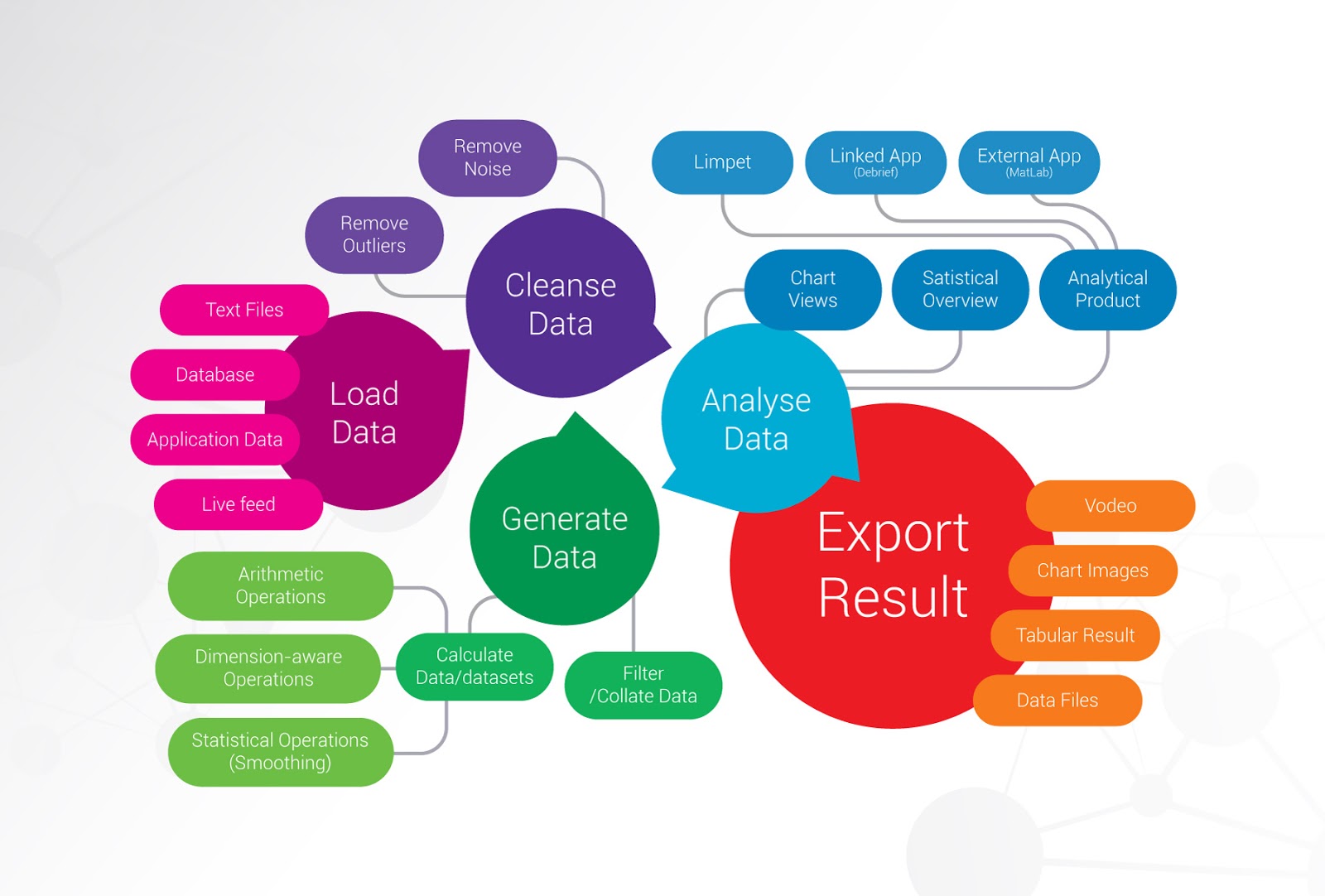
The generic nature of this approach (it’s certainly not tied to the maritime domain) means that it is justified to create the capabilities as a separate project, seamlessly pulling capabilities back into the Debrief interface. Notice the new measurements elements in the Debrief Outline view at the bottom left of the following screenshot
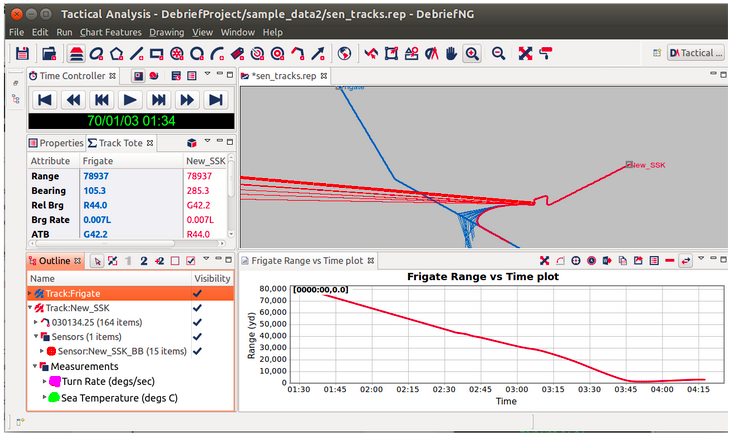
The new capability is being called Limpet (Lightweight InforMation ProcEssing Toolkit), and we'd like to tell you more about it.
What’s Special About Limpet
- Limpet will focus on allowing users to conduct Data Driven Analysis:
- Analysis is based on sound scientific principles
- Allows analysts to work at high level, with quick results
- Limpet will allow a quick-start in new analysis domains
- Users can drag in data-files directly, without worrying about import conversion
- A Descriptive statistics view gives quick overview of datafiles
- Exploratory analysis tools let analysts learn about equipment / sensor / system performance
- The software will be extensible to accommodate emergent/proprietary file formats
- The capabilities are extensible to new scientific domains through the addition of new operations
- Limpet will offer organisation-wide benefits
- This open source software will suffer no vendor lock in
- The common skill-set can be applied across multiple domains
- Limpet includes a wide range of functions and analysis options, from the generic level (addition of datasets) to domain-specific (calculate the acoustic propagation loss between two vessel tracks).
How Is It Different From Debrief?
Debrief focuses on the spatial (map based) analysis of a specific set of data from maritime vehicles. Limpet supports graphical and tabular analysis of an unlimited range of datasets coming from any source..
What Are The Alternatives?
There are two traditional bodies of application that are used in this ad-hoc analysis
- Excel/MatLab: Limpet takes away tasks of loading, parsing and organising data, letting analyst concentrate on actually performing analysis via a library of high level operations. Basic administrative tasks are automated, thus cutting down on turnaround time. Many more features are provided in Limpet, these features free up more of the analyst’s time to focus on analysis rather than clerical data tasks.
- ETL (Talend, Pentaho, Knime, PTolemy II) : Limpet supports the direct, interactive manipulation of datasets with instant responses. It is possible to collate multiple operations into a composite operation for later usage (like traditional ETL), but the Limpet UI flow allows the analyst to develop these operations in the more exploratory, experimental manner necessary when investigating a new domain. Real-time data manipulation tools allow for faster turnaround of analysis.
Where Can I Get Limpet?
Limpet is still under development. Things are pretty embryonic right now - we're still going through high level requirements collection,. But, we hope to motor on through the high level questions, discussions, plans, designs, and get into some nice iterative/agile progress in September.
You can track Limpet updates on it’s Github page: https://github.com/debrief/limpet. We encourage you to subscribe to our mailing list for updates: https://groups.google.com/d/forum/limpet-tool.

Ian Mayo
Ian Mayo (from Deep Blue C Technologies) has been developing and maintaining Debrief since 1995, and helping users perform effective analysis and deliver persuasive results.